接下來我們來介紹 ETL Job
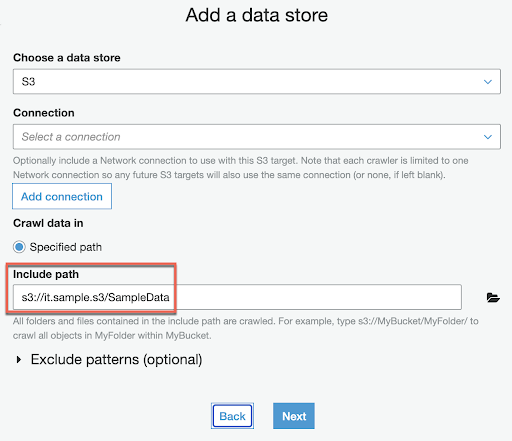
在開始之前我們需要先準備資料源
it.sample.s3
㇄SampleData
㇄order
⎢ ㇄orders.csv
㇄order_products_prior
⎢ ㇄order_products__prior.csv
㇄order_products_train
⎢ ㇄order_products__train.csv
㇄products
⎢ ㇄products.csv
㇄sample_submission
⎢ ㇄sample_submission.csv
㇄departments
⎢ ㇄departments.csv
㇄aisles
㇄aisles.csv
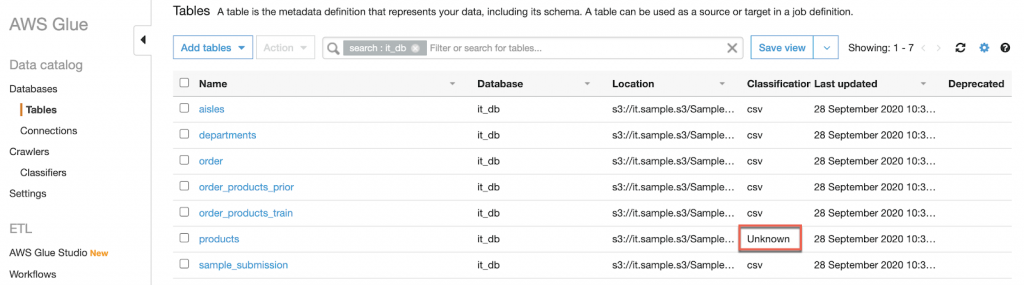
在遇到比較大的資料無法使用編輯器進行處理時,則可以使用 Linux CMD 進行字元替換sed -i 's/\/""//g' products.csvs/:代表執行替換功能\/"":代表要替換的字元 /""//:代表替換後的字元
而找出錯誤的方式可以使用二分法或是減少資料筆數先讓 Crawler 可以正常運作,這次 troubleshooting 的方式就是先將資料筆數固定在前1000 筆資料,再透過二分法找出有問題的資料欄位


 iThome鐵人賽
iThome鐵人賽